robots.txt file is a very small text file that we have to keep in the root folder of our site. This tells the search engine bots that, which part of the site to be crawl or indexed and which part not need to crawl.
If you make a slight mistake while editing or customizing it, then the search engine bots will stop crawling or indexing your site and your site will not be visible in the search results.
In this tutorial, we will see what is robots.txt file and how to create perfect robots.txt file for SEO.
Why robots.txt file is necessary for website
When the search engine bots come to the website or blog, they follow the robots.txt file and then crawl the content. But if there is no file of robots.txt in your site, then the search engine bots will start indexing and crawling all the contents of the website that you do not want to index.
The search engine bots search the robots file before indexing any website. When they do not find any instruction by the robots.txt file, then they start indexing all the contents of the website. But if any instruction is found then the search engine bots follow them then Index website or webpage accordingly.
For these reasons robots.txt file is required. If we do not give instructions to the search engine bots through this file, then they index our entire website and also index some data that you did not want to index.
Benefits of robots.txt file
- This tell search engine bots that which part of the site to crawl and index and which part to not.
- A particular file, folder, image, PDF, etc. can be prevented from being indexed in the search engine.
- Sometimes it happens that all the search engine crawlers on our website come together that affect the performance of our website, then you can get rid of this problem by adding crawl-delay in robots.txt file.
- You can privateize the entire section of any website.
- Can prevent the internal search result page from appearing in the SERPs.
- You can improve your website SEO by blocking low quality pages.
Where does robots.txt File reside in the website
If you are a wordpress user,then robots.txt file reside in the root folder of your site. If this file is not found in this location, then search engine bots start indexing your entire website.
If you want to know whether there is robots.txt file add on your website or not, then you just have to type "example.com/robots.txt" in your search engine address bar.
After this a text page will open in front of you as you seeing in the screenshot given below.
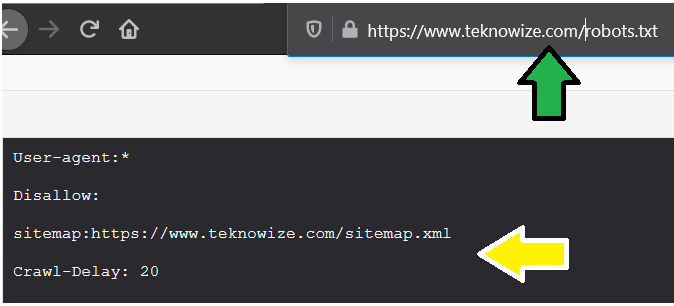
This is robots.txt file of teknowize. If you do not see any such text page, then you will have to create a robots.txt file for your site.
Basic format of robots.txt file
The basic format of robots dot pst file is very simple and looks like this :-
- User-agent: [ user – agent name ]
- Disallow: [ URL of the page you don't want to crawl ]
These two commands are considered to be a complete robots.txt file, although a robots file can contain many command of user agents and directives ( disallow, allow, crawl-delays etc.)
- User-agent: If you want to give same instruction to all search engine bots, then use " * " after user agent like - User-agent: * .
- Disallow: This prevent file and directories from being indexed.
- allow: This allows the search engine bots to have your content crawled and indexed.
- Crawl-delay: How many seconds the bots has to wait before loading and crawling the page content.
Preventing all web crawlers from indexing websites
User-agent: *
Disallow: /
Using this command in robots.txt file, you can prevent all web crawlers or bots from crawling the website.
Allow all web crawlers to index all contents
User-agent: *
Disallow:
Using this command in robots.txt file, you can allow all web crawlers or bots to crawling the website.
Blocking a specific folder for a specific web crawler
User-agent: Googlebot
Disallow: /example-subfolder/
This command only prevents the Google crawler from crawling the 'example-subfolder', but if you want to block all the crawler, then your robots file like -
User-agent: *
Disallow: /example-subfolder/
Preventing any one specific page from being indexed
User-agent: *
Disallow: /page URL
This will prevent all crawlers from crawling your page URL, but if you want to block a specific crawler, then you write robots file like this -
User-agent: Googlebot
Disallow: /page URL
This command will only prevent Google from crawling your page URL.
Add a sitemap to the robots.txt file
Sitemap: https://www.example.com/sitemap.xml
You can add your sitemap to robot.txt file anywhere.